# 解释器
# Python解释器是Python程序运行的核心
# 我们写的python代码是人类能够看懂的高级语言,而计算机只能看懂由0和1组成的机器语言
# 解释器就是负责读取Python代码(即.py文件)并将其转换为机器语言,从而使计算机能够执行
# 简单来说,Python解释器就像是Python代码与计算机之间的翻译官,把Python代码翻译成计算机能懂的语言
配置项目解释器
# 打开 PyCharm 项目
# 点击File -> Settings -> Project: [项目名称] -> Python Interpreter
# 选择项目所使用的 Python 解释器。如果没有合适的解释器,可以点击右上角的齿轮图标
# 选择Add来添加新的解释器,如系统安装的 Python 解释器或虚拟环境解释器
# pip 介绍
- python 命令
python # 查看当前python版本信息
- 使用 pip 命令
# 查看已安装的 Python 包列表
pip list
pip freeze > requirements.txt # 生成快照
pip freeze | findstr django
python.exe -m pip list
py -3.9 -m pip install numpy
# 安装包文件
pip install pandas
pip install numpy==1.21.0
# 查看包信息
pip show pandas
# 可以通过如下命令,让其连接国内的网站进行包的安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
# 修改配置文件,没有就创建一个
# Linux目录:~/.pip/pip.conf
# Windows目录:pip show numpy # 查看某个包的安装路径(以 numpy 为例)
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple # 清华源
index-url = https://pypi.douban.com/simple # 豆瓣源
index-url = https://mirrors.aliyun.com/pypi/simple # 阿里云
- PyCharm 安装第三方包
# 在 PyCharm 中,点击File -> Settings -> Project: [项目名称]
# 在 Python Interpreter 页面中,点击+号
# 在弹出的 Available Packages 窗口中搜索需要的依赖库,如pandas、numpy等
# 选中后点击 nstall Package 按钮,PyCharm 会自动下载并安装该库到项目的解释器环境中
- 手动导入本地库
# 添加本地库路径
# 有一些本地开发的依赖库或第三方库的本地副本,需要将其所在的文件夹路径添加到项目的Python Path中
# 在 PyCharm 中,点击File -> Settings -> Project: [项目名称] -> Project Structure
# 点击 Add Content Root 或 Add Source Root 按钮,选择本地库所在的文件夹,将其添加到项目结构中
# 标记为依赖库
# 在项目的Python Path中添加本地库路径后,还需要在 Python Interpreter 页面中
# 右键点击添加的本地库文件夹,选择 Mark as -> Sources Root 或 Mark as -> Test Sources Root 等
# 将其标记为相应的源文件或测试文件根目录,以便 PyCharm 正确识别和加载其中的模块
# Anaconda
官网 (opens new window) 开源镜像下载站 (opens new window) 搜索到10年前的包 (opens new window)
- Anaconda是conda的完整版本,内置了将近300个关于服务端开发
- Anaconda里面预装好了conda、某个版本的python、众多packages、科学计算工具等等
- conda 核心功能是包管理与环境管理,允许用户方便地安装不同版本的python并可以快速切换
- Miniconda是conda的简单版本,内置了将近30个常用第三方模块 miniconda下载地址 (opens new window)
# Windows 添加环境变量(默认会添加) path:
# C:\ProgramData\miniconda3
# C:\ProgramData\miniconda3\Scripts
# linux
# 下载
wget -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda-1.4.0-Linux-x86_64.sh
# 运行安装脚本
bash Anaconda-1.4.0-Linux-x86_64.sh
# 如果您已经为脚本文件添加了执行权限,也可以直接运行
./Anaconda-1.4.0-Linux-x86_64.sh
# Anaconda 的安装路径
ls ~/anaconda3/bin/conda
# 手动添加 PATH
echo 'export PATH="~/anaconda3/bin:$PATH"' >> ~/.bashrc
# 重新加载您的bash配置文件
source ~/.bashrc
# 查看conda版本,安装成功
root@ubuntu:~# conda -V
# 检查是否安装成功
conda --version
conda info
python
# 仓库源切换到国内镜像
# 1. 显示当前存在的下载源
conda config --show channels
# 2. 生成 .condarc 配置文件(如果没有)
conda config --set show_channel_urls yes
# 3. 添加清华镜像源(国内推荐)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
# 4. 设置搜索时显示通道地址
conda config --set show_channel_urls yes
# 5. 清除索引缓存
conda clean -i
# conda 常用命令
conda create -n <环境名> python=3.1.12 # 创建虚拟环境
conda activate <环境名> # 激活环境,以使用该环境(安装的包将会在此环境下)
conda deactivate # 从当前环境返回到基础(root)环境或者之前所在的环境
conda env list # 列出所有环境
conda env remove -n <环境名称> # 删除指定环境
conda list # 查看环境中的所有包
conda list -n <环境名> # 查看环境中的所有包
conda list <包名> # 查看某个包的信息
conda install # 安装 XXX 包
conda install <包名1>==<版本号>
conda remove # 删除XXX 包
conda remove <包名1>==<版本号>
# 优先尝试用conda安装所有依赖(更稳定)
conda install --file requirements.txt
# 如果上述步骤报错(部分包conda找不到),使用pip安装剩余依赖
pip install -r requirements.txt
# 包被安装的位置
- 基础环境下包的安装位置
Windows 系统 # C:\ProgramData\Anaconda3\pkgs或C:\Users\[用户名]\Anaconda3\pkgs目录
Linux 系统 # /home/[用户名]/anaconda3/pkgs或者/opt/anaconda3/pkgs路径中
- 虚拟环境下包的安装位置
Windows 系统 # C:\Users\[用户名]\Anaconda3\envs\[虚拟环境名]\Lib\site-packages目录
Linux 系统 # /home/[用户名]/anaconda3/envs/[虚拟环境名]/lib/python[版本号]/site-packages路径下
# PyCharm 中使用已安装的虚拟环境
# conda的路径是重点,必须选择anaconda -> condabin -> conda.bat
# 如果已经指定conda环境解释器,出现no conda environment selected,下图操作:
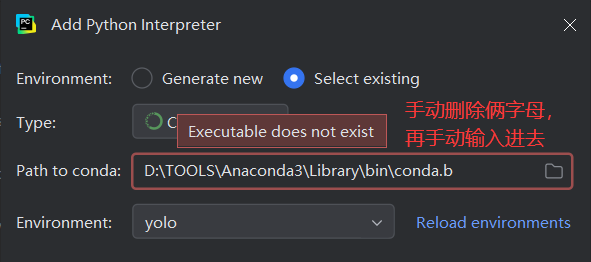
# conda 使用 Poetry 的包
# 1、在 Conda 环境中安装 Poetry
pip install poetry==1.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 2、设置阿里云镜像源
poetry source show
poetry source remove aliyun # 移除默认镜像源
poetry source add --priority=default aliyun https://mirrors.aliyun.com/pypi/simple/
# 3、更新 poetry.lock 文件
poetry lock --no-update
# 3、若无需 Conda 的特定功能,可直接在 Conda 环境中运行 Poetry 命令管理依赖:
poetry install # 自动读取 poetry.lock 并安装依赖
# 基础语法
# 注释
- 单行注释
# 这是一段输出hello world的代码
print('hello world')
- 多行注释,用三个引号引起来
"""
哈哈哈
人生苦短
我学python
"""
注意
在pycharm中,可以使用ctrl+?快速进行内容的注释
# 转义字符
\b # 退格
\e # 转义
\n # 换行
\t # 横向制表符
\' # 单引号
注意
python 中,字符串前面加上 r 表示原生字符串
print('abc\n123') # abc 换行 123
print('abc\\n123') # abc\n123
print(r'abc\n123') # abc\n123
# 数据类型
- 可变类型与不可变类型的定义
# 可变数据类型其实就是值在发生改变的时候,内存地址不变,但是原值在变
# 列表、字典、集合
# 不可变的数据类型其实就是修改值的时候,它的内存地址也发生了改变,从而产生了新的值
# 字符串、数字(整型、浮点型、布尔)、元组
- 整型 int
i:int = 100;
# 数字也可以加下划线,与不加下划线并无区别
print(1_2_3)
- 浮点型 float
Π:float = 3.1415926
# 在Python中,表示较大的数时,也可以使用科学计数法
# 1e6表示1000000.0,其中e表示x10,也就是1x10^6
# 这里的1e6其实并不是整数,可以看到后面保留了一位小数,属于浮点型
# 浮点数一般都会有误差,计算机只会识别0和1的二进制数,而在浮点数转换为二进制时,会出现偏差
- 布尔类型 bool
a:bool = True
# 在python中True表示真,False表示假
# 真也可以用1表示,假也可以用0表示
# 在python也有一些特殊值表示Fasle,除开这些特殊值,其他转bool值都是True
# 0、""、[]、()、{}、set()、None
# None类型的应用场景:
# 1、用在函数无返回值上
# 2、在if判断中,None等同于False
# 3、用于声明无内容的变量上:name = None
- 字符串 str
# 相比与java和c来讲,python的字符串是可以通过双引号或者单引号来定义字符串的
print("ab")
print('哈哈哈')
# 多行字符串
print("""
春眠不觉晓,处处闻啼鸟。
夜来风雨声,花落知多少。
""")
# 字符串的格式化方式一
name = "张三"
age = 18
height = 178.5
province = "山东省"
city = "济南市"
message ="姓名 %s" % name # s 取代字符串,也能取代数字
message ="年龄 %d" % age # d 取代数字
message ="身高 %f" % height # f 取代浮点数
message ="所在省份 %s,城市 %s" % (province,city) # 多个变量要用括号括起来
# 数字精度控制
%5d # 表示将整数的宽度控制在5位
# 如数字11,被设置为5d,就会变成:[空格][空格][空格]111,用三个空格补足宽度
%5.2f # 表示将宽度控制为5,将小数点精度设置为2
# 小数点和小数部分也算入宽度计算,如对11.345设置了%7.2f后,结果是:[空格][空格]11.35
# 字符串的格式化方式二
# f"内容{变量}"的格式来快速格式化,这种方式:不理会类型,不做精度控制
print(f"我是{name},年龄:{age},身高:{height}")
# 字符串前面加 r 表示创建一个原始字符串
normal_string = 'C:\new_folder\test.txt' # 普通字符串
print(normal_string) # 输出 C: ew_folder est.txt
raw_string = r'C:\new_folder\test.txt' # 原始字符串
print(raw_string) # 输出 C:\new_folder\test.txt
# 字符串前面加 b 表示将字符转换二进制流,不包括中文
a = b'hello'
print(a) # b'hello'
# 将所有字符转二进制流,包括中文
b = '你好'.encode('utf-8')
print(b) # b'\xe4\xbd\xa0\xe5\xa5\xbd'
e = b.decode('utf-8')
print(e) # 你好
f = '你好'.encode('gbk')
print(f) # b'\xc4\xe3\xba\xc3'
g = f.decode('gbk')
print(g) # 你好
# 字符串常用方法
字符串[下标] # 根据下标索引取出特定位置字符
字符串.index(字符串) # 查找给定字符的第一个匹配项的下标
字符串.replace(字符串1,字符串2) # 将字符串内的全部字符串1,替换为字符串2
字符串.split(字符串) # 按照给定字符串,对字符串进行分隔
字符串.strip()/字符串.strip(字符串) # 移除首尾的空格和换行符或指定字符串
字符串.count(字符串) # 统计字符串内某字符串的出现次数
len(字符串) # 统计字符串的字符个数
- 列表 list
# 列表就是一组有序且可变的数据集合
# 允许重复数据存在
# 可以容纳不同类型的元素
# 使用 [] 表示
lst = [] # 创建一个空列表
name_lst = ['小张','小石','小毅','小昊',100] # 初始化一个列表
name_lst = [[1, 2, 3], [4, 5, 6]] # 嵌套的列表
# 可以反向索引,也就是从后向前:从-1开始,依次递减(-1、-2、-3......)
print(name_lst[-1]) # 结果:100
print(name_lst[-2]) # 结果:小昊
# 常用方法
列表.append(元素) # 向列表中追加一个元素
列表.extend(容器) # 将数据容器的内容依次取出,追加到列表尾部
列表.insert(下标,元素) # 在指定下标处,插入指定的元素
del 列表[下标] # 删除列表指定下标元素
列表.pop(下标) # 删除列表指定下标元素,返回删除的元素
列表.remove(元素) # 从前向后,删除此元素第一个匹配项
列表.clear() # 清空列表
列表.count(元素) # 统计此元素在列表中出现的次数
列表.index(元素) # 查找指定元素在列表的下标找不到报错
len(列表) # 统计容器内有多少元素
# 列表的 sort 方法
my_list = [["a",33],["b",55],["c",11]]
my_list.sort(key=lambda x:x[1])
print(my_list)
- 元组 tuple
# 元组就是一组数据的集合,其数据只能访问而不能改变
# 允许重复数据存在
# 可以容纳不同类型的元素
# 使用 () 表示
content = () # 设置一个空元组
content1 = tuple() # 设置一个空元组
content2 = (1, '小张', True)) # 初始化一个元组
content3 = ('大表哥',) # 只有一个元素的元组
content4 = ((1,2,3),(4,5,6)) # 元组的嵌套
print(type(content)) # 查看其类型
# 不需要小括号也是可以的,但是必须得有逗号进行分隔,就算只有一个元组,也要用逗号进行分隔
cont = "小石","小毅","小昊"
# 常用方法
num = t5[1][2] # 下标索引专取出内容
元组.index(元素) # 查找某个数据,如果数据存在返回对应的下标,否则报错
元组.count(元素) # 统计某个数据在当前元组出现的次数
len(元组) # 统计元组内的元素个数
# 合并元组
t1 =(1, 2)
t2 =(2, 4)
print(t1 + t2) # (1, 2, 2, 4)
元组本身不可变,但如果元组包含其他可变的元素,那些可变元素可以改变
t9=(1,2,["itheima","itcast"])
t9[2][1] = 'best'
print(t1) # 结果: (1,2,['itheima',best'])
- 集合 set
# 集合就是一组不重复、且无序的一组数据集合
# 集合是无序的,所以集合不支持:下标索引访问
# 集合和列表一样,是允许修改的
# 使用 {} 表示
cont = set() # 定义一个空集合,必须使用set()
cont2 = {2, 4, 5 , 1, 2, 3} # 给集合初始化值
print(cont2) # 会输出有序且无重复的集合 {1, 2, 3, 4, 5}
# 集合的数学运算
set1 = {1,2,3}
set2 = {4,5,6,1,2}
print(set1&set2) # 输出两个集合的交集
print(set1|set2) # 并集
print(set1-set2) # 输出set1中去除set2的元素
print(set2-set1) # 输出set2中去除set1的元素
print(1 in set1) # 看1是否在set1中
print(7 not in set2) # 看7是否不在set2中
# 常用方法
集合.add(元素) # 集合内添加一个元素
集合.remove(元素) # 移除集合内指定的元素
集合.pop() # 从集合中随机取出一个元素
集合.clear() # 将集合清空
集合1.difference(集合2) # 得到一个新集合,内含2个集合的差集
集合1.difference_update(集合2) # 在集合1中,删除集合2中存在的元素
集合1.union(集合2) # 得到1个新集合,内含2个集合的全部元素
len(集合) # 得到一个整数,记录了集合的元素数量
注意
集合是不能存储可变数据类型的,只能存储不可变数据类型
- 字典 dict
# 主要是不重复无序的,主要采用键值对的方式来存储数据
# 字典的 Key 和 Value 可以是任意数据类型
# 字典是可以嵌套的
dic1 = {} # 创建一个空字典
dict2 = dict() # 创建一个空字典
dict3 = {'name':'小石', 'age':18, 'hobby':'战斗'}
# 常用方法
print(dic['name']) # 通过键值对的方式去访问值
dic['name'] = '小张' # 修改字典的'name'值
字典.pop(Key) # 取出Key对应的Value并在字典内删除此Key的键值对
字典.clear() # 清空字典
字典.keys() # 查看所有键,返回列表
字典.values() # 查看所有的值,返回列表
字典.items() # 可理解为'项',查看所有(键,值),返回列表
len(字典) # 计算字典内的元素数量
# zip 拉链函数
a =['a1','a2','a3','a4']
b =['b1','b2','b3']
c = zip(a, b)
print(c) # 返回对象的地址
print(dict(c)) # 转换为字典 {'a1': 'b1', 'a2': 'b2', 'a3': 'b3'}
注意
- 字典是不重复的,字典的键如果相同,就取最后一个重复键的值
- 新增和更新元素的语法一致,如果Key不存在即新增,如果Key存在即更新
- 容器通用功能
通用for循环 # 遍历容器(字典是遍历key)
max()/min()/len() # 容器内最大、小元素,个数
str() # 转字符串
int() # 转整型
bool() # 转布尔值
list() # 转换为列表
tuple() # 转换为元组
set() # 转换为集合
sorted(序列,[reverse=True]) # 排序,reverse=True表示降序
# 列表推导式
listl = [i for i in range(10)]
print(list1) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 元组推导式
tl = (i for i in range(10))
print(t1) # (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
# 列表拆包
a,*b = 1,2,3
print(a,b) # 1 [2, 3]
# 字典拆包
a,b,c = {'name':'Wilia','age':18,'gender':'女'}
print(a,b,c) # name age gender
- 切片的使用:左闭右开,顾头不顾尾
# 语法 : 序列 [起始下标 : 结束下标 : 步长]
# 表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列
# 起始下标表示从何处开始,可以留空,留空视作从头开始
# 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
# 对list进行切片:从1开始,4结束,步长1
my_list = [0, 1, 2, 3, 4, 5, 6]
result1 = my_list[1:4] # [ 1, 2, 3 ] 步长默认是1,所以可以省略不写
# 对tuple进行切片,从头开始,到最后结束,步长1
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result2 = my_tuple[:] # 起始和结束不写表示从头到尾,步长为1可以省略
# 对str进行切片,从头开始,到最后结束,步长2
my_str = "01234567"
result3 = my_str[::2] # 0246
# 对str进行切片,从头开始,到最后结束,步长-1
my_str = "01234567"
result4 = my_str[::-1] # 76543210 等同于将序列反转了
# 对列表进行切片,从3开始,到1结束,步长-1
my_list = [0, 1, 2, 3, 4, 5, 6]
result5 = my_list[3:1:-1] # [3, 2]
# 对元组进行切片,从头开始、到尾结束,步长-2
my_tuple = (0, 1, 2, 3, 4, 5, 6)
result6 = my_tuple[::-2] # (6, 4, 2, 0)
# 深浅拷贝
import copy
a = [1, 2, 3, 4, ['a', 'b']]
# 对象拷贝,浅拷贝
b = copy.copy(a)
a[0]=5 # 修改原数据a第一层的值
print(b) # 复制后的数据不会随着变化 输出:[1, 2, 3, 4, ['a', 'b']]
a[4][0]='c' # 修改原数据a第二层的值
print(b) # 复制后的数据会随着变化 输出:[1, 2, 3, 4, ['c', 'b']]
c = copy.deepcopy(a) # 对象拷贝,深拷贝
a[0]=6 # 修改原数据a第一层的值
print(c) # 复制后的数据不会随着变化 输出:[1, 2, 3, 4, ['c', 'b']]
a[4][0]='d' # 修改原数据a第二层的值
print(c) # 复制后的数据不会随着变化 输出:[1, 2, 3, 4, ['c', 'b']]
注意
- 深拷贝:完全复制,原数据发生变化,备份数据不会有任何影响
- 浅拷贝:半复制半数据共享,原数据第二层发生变化,备份数据也会随之发生变化
# 运算符
- 算术运算符
除 / # x 除以 y,除出来的数应该是一个小数
取整数 // # 返回商的整数部分(向下取整),9 // 2 ——>4
幂 ** # x的y次幂 a**b为10的20次方
- 成员运算符 in、not in
lst = [1,2,3,4] # 定义一个列表
print(1 in lst)
print(1 not in lst)
>> True
>> False
- 身份运算符 is、is not
# is和==有区别,==只是看两个值是否长得一样,is是比较内存地址
# 可以用id()查看一个值的内存地址
# 判断语句
# 定义变量
age = 30
# 进行判断
if age >= 18 and age!= null:
print("我已经成年了") # 需要4个空格作为缩进
elif age >= 40:
print("我已经中年了") # 需要4个空格作为缩进
else:
print("我已经老年了") # 需要4个空格作为缩进
# 循环语句
- while 循环
# 定义变量
i = 0
# 进行判断,基于空格缩进来决定层次关系
while i < 100:
print("hello") # 需要4个空格作为缩进
i += 1
j = 1
while j <= 10:
print(f"送给小美第{j}只玫瑰花")
j += 1
- for 循环
#定义字符串name
name="itheima"
# for循环,本质上是遍历:序列类型
for x in name:
print(x)
- range 循环
range(num) # 从0开始到num结束的数字序列(不含num本身)
range(num1,num2) # 从num1开始到num2结束的数字序列(不含num2本身)
range(num1,num2,step) # 从num1开始到num2结束的数字序列(不含num2本身),step步长(默认为1)
for x in range(5):
print(x) # 0,1,2,3,4
for x in range(5,10):
print(x) # 5,6,7,8,9
for x in range(5,10,2):
print(x) # 5,7,9
# 函数的用法
- 函数的定义
def add(x, y):
"""
函数说明
:param x: 参数1
:param y: 参数2
:return: 返回值
"""
num = x + y
print(f"{x} + {y}的结果是: {num}")
# 调用函数
add(5, 6)
注意
- 如果函数没有使用 return 语句返回数据,实际上就是返回了 None 这个字面量
- 如果将函数定义为 class(类) 的成员,那么函数会称之为方法
- global 和 nonlocal
# global:可以在函数内部声明变量为全局变量
a = 10
def func():
global a # 声明 a 为全局变量
print(a) # 10
a = 20
func()
print(a) # 20
# nonlocal:对父级作用的变量进行引用和修改,并且引用的哪层,就从那层开始及以下,此变量全部发生改变
a = 10
def funa():
a = 20
def funb():
nonlocal a # a 是funa函数中的局部变量
print("funb函数中的a的值",a) # 20
a = 30
funb()
print("funa函数中的a的值",a) # 30
funa()
print(a) # 10
- 查看函数的说明文档
import copy
# help()
help(copy)
# 或者
print(copy.__doc__)
- 多个返回值的函数
def test return():
return 1,"hello", True
x,y,z = test_return
print(x) # 结果 1
print(y) # 结果 hello
print(z) # 结果 True
# 按照返回值的顺序,写对应顺序的多个变量接收即可
# 支持不同类型的数据 return
- 位置参数:调用函数时根据函数定义的参数位置来传递参数
def user_info(name, age, gender):
print(f'您的名字是:{name}, 年龄是{age}, 性别是{gender}')
# 传递的参数和定义的参数的顺序及个数必须一致
user_info('TOM', 20,'男')
- 关键字参数:函数调用时通过 "键=值" 形式传递参数
def user info(name, age, gender):
print(f"您的名字是:{name}, 年龄是:{age}, 性别是:{gender}")
# 关键字传参
user_info(name="小明", age=20, gender="男")
# 可以不按照固定顺序
user_info(age=20, gender="男", name="小明")
# 可以和位置参数混用,位置参数必须在前,且匹配参数顺序
user_info("小明", age=20, gender="男")
- 缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值
def user_info(name, age, gender='男'):
print(f'您的名字是:{name}, 年龄是{age}, 性别是{gender}')
# 传递的参数和定义的参数的顺序及个数必须一致
user_info('TOM', 20, '男')
user_info('Rose', 18, '女')
- 不定长参数:不定长参数也叫可变参数:用于不确定调用的时候会传递多少个参数
# 位置传递 *args
def user_info(*args):
print(args)
# 传进的所有参数都会被args变量收集,合并为一个元组(tuple),args是元组类型
user_info('ToM', 18)
# 关键字传递 **kwargs
def user_info(**kwargs):
print(kwargs)
# 传进的所有参数都会被kwargs变量收集,合并为一个字典(dict),kwargs是字典类型
user_info(name='小王', age=11, gender='男孩', addr='北京')
- 函数作为参数传递
# 函数 compute 作为参数,传入了test_func函数中使用
def test_func(compute):
result =compute(1, 2)
print(result)
def compute(x, y):
return x+y
test_func(compute) # 结果:3
- lambda匿名函数
# def关键字,可以定义带有名称的函数,可以基于名称重复使用
# lambda关键字,可以定义匿名函数(无名称),只可临时使用一次
def test_func(compute):
result = compute(1,2)
print(result)
# 通过lambda关键字,传入一个一次性使用的lambda匿名函数
# 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
test_func(lambda x,y:x+y)
# 闭包
在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包
def account(initial_amount = 0):
def atm(num, deposit=True):
# 需要使用nonlocal关键字修饰外部函数的变量才可在内部函数中修改它
nonlocal initial_amount
if deposit:
initial_amount += num
print(f"存款:+{num},账户余额:{initial_amount}")
else:
initial_amount -= num
print(f"取款:-{num},账户余额:{initial_amount}")
return atm
fn = account()
fn(300)
fn(200)
# 装饰器
装饰器本质是一种闭包,在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能
- 标准版装饰器
def outer(func):
def inner(*args, **kwargs):
print('执行前')
res = func(*args, **kwargs)
print('执行后')
return res
return inner
- 装饰器的一般写法(闭包写法)
def sleep():
import random
import time
print("睡眠中......")
time.sleep(random.randint(1,5))
f = outer(sleep)
f()
# 执行前
# 睡眠中......
# 执行后
- 装饰器的语法糖写法
# 使用@myFunc定义在目标函数sleep之上
@myFunc
def sleep():
import random
import time
print("睡眠中......")
time.sleep(random.randint(1,5))
sleep()
# 执行前
# 睡眠中......
# 执行后
- 多层嵌套装饰器
def outer(func):
def func(x,y):
print(x,y)
def inner(a, b):
print('执行前')
res = func(a, b)
print('执行后')
return res
return inner
return func
@outer
def index(a, b):
print(a, b)
# 调用方式
index(1, 2)(3, 4)
# 1 2
# 执行前
# 3 4
# 类的使用
# 基础介绍
# 定义类
class Student:
# 成员属性可以不用定义
name: str
age: int
grade: int = 0 # 默认值
# 构造方法,返回none
def __init__(self, name: str, age: int, grade: int) -> None:
self.name = name
self.age = age
self.grade = grade
# 打印对象时,返回自定义的能容
def __str__(self):
return f"Person(name={self.name}, age={self.age}, grade={self.grade})"
# 方法,返回int
def get_grade(self) -> int:
return self.grade
# 创建类对象,导包
from Stu import Student
# 不需要 new
stu = Student("张三", 20, 99)
stu.get_grade()
self 关键字是成员方法定义的时候,必须填写的
- 它用来表示类对象自身的意思,用于访问类对象的属性和方法
- 当我们使用类对象调用方法的是,self会自动被python传入
- 在方法内部,想要访问类的成员变量,必须使用self
# 析构函数
- 删除对象的时候,Python解释器默认会调用的方法,用于清除对象占用的内存空间
- 析构函数不能有参数,没有返回值,一个类只有一个析构函数
- 整个逻辑功能执行完后自动执行
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
print("初始化")
def __del__(self):
print("被销毁")
person = Person("Alice", 30)
print("测试代码1")
print("测试代码2")
def func():
print("测试代码3")
print("测试代码4")
func()
# 初始化
# 测试代码1
# 测试代码2
# 测试代码3
# 测试代码4
# 被销毁
- 手动执行
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
print("初始化")
def __del__(self):
print("被销毁")
person = Person("Alice", 30)
del person
print("测试代码")
# 初始化
# 被销毁
# 测试代码
# 私有成员
- 私有属性和方法,不能通过对象直接访问,可以在本类内部使用
- 不能被子类继承,子类也无法访问
class Student:
# 私有成员变量:变量名以__开头(2个下划线)
__gender: str
# 私有成员方法:方法名以__开头(2个下划线)
def __getGender(self):
return self.__gender
# 可以被其它的成员使用
def __init__(self, name: str, age: int, gender: str) -> None:
self.name = name
self.age = age
self.__gender = gender
# 可以被其它的成员使用
def __str__(self):
return f"Student类对象,name={self.name},age={self.age},gender={self.__gender}"
- 强行获取私有属性、私有方法
stu = Student("zs", 18, "男")
print(stu._Student__gender)
print(stu._Student__getGender())
# 类的继承
- 单继承
# Person类
class Person:
name:str
def getName(self):
return self.name
# Student类
from Per import Person
class Student(Person):
def __init__(self, name: str, age: int, grade: int, gender: str) -> None:
self.name = name
self.age = age
self.grade = grade
self.__gender = gender
def get_grade(self) -> int:
return self.grade
- 多继承
class MyPhone(Phone,NFCReader,RemoteControl):
# 本身没有自己的方法
pass
注意事项
多继承中,如果有同名的成员,默认的继承顺序为从左到右,即先继承的保留,后继承的被覆盖
MyPhone.__mro__ # 查看调用顺序的方法
# 类的重写
- 覆盖父类的方法:在子类中定义一个和父类同名的方法来实现
class phone:
IMEI = None #序列号
producer = "ITCAST" #厂商
def call_by_5g(self):
print("父类的5g通话")
class MyPhone(phone):
# 重写父类属性
proucer = "ITHEIMA"
# 重写父类方法
def call_by_5g(self):
print("子类的5g通话")
- 对父类方法进行扩展:
# 父类名.方法名(self)
# super().方法名()
class phone:
IMEI = None #序列号
producer = "ITCAST" #厂商
def call_by_5g(self):
print("父类的5g通话")
class MyPhone(phone):
proucer = "ITHEIMA"
def call_by_5g(self):
# 方式一
# 父类名.成员变量
print(f"父类的品牌是:{phone.producer}")
# 父类名.成员方法(self)
phone.call_by_5g(self)
# 方式二
# 用super().成员变量
print(f"父类的品牌是:{super().producer}")
# super().成员方法()
super().call_by_5g()
print("子类的5g通话")
# 类的多态
多态常作用在继承关系上,以父类做定义声明,以子类做实际工作,用以获得同一行为的不同状态
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
print("汪汪汪")
class Cat(Animal):
def speak(self):
print("喵喵喵")
def make_noise(animal: Anima1):
anima1.speak()
dog = Dog()
cat = Cat()
make_noise(dog) # 输出:汪汪注
make_noise(cat) # 输出:喵喵喵
# 抽象类(接口)
父类用来确定有哪些方法,具体的方法实现,由子类自行决定
抽象类 # 含有抽象方法的类称之为抽象类
抽象方法 # 方法体是空实现的(pass)称之为抽象方法
# 类方法
- 使用装饰器 @classmethod 来表示其为类方法
- 第一个参数必须是类对象,一般以cls作为第一个参数
- 在类方法内部可以直接访问类属性,或调用类方法
class Student:
age = 20
@classmethod
def getAge(cls, age):
cls.age = age
return cls.age
stu = Student()
print(stu.getAge(10))
# 可以通过类名直接调用
print(Student.getAge(30))
# 静态方法
使用装饰器 @staticmethod 来表示其为类方法
class Student:
age = 20
@staticmethod
def getAge():
return A.age
stu = Student()
stu.getAge() # 实例对象可以访问静态方法
Student.getAge() # 类对象可以访问静态方法
# 普通方法
class Student:
age = 20
# 参数没有加self
def getAge():
return A.age
Student.getAge() # 类名+方法名调用
# __new__方法的使用
- 是第一个在创建对象时真正被调用的方法
- 作用:在内存中为对象分配空间,返回值会引发__init__()调用
# __new__() 没有返回值的情况,不执行__init__()
class Student:
def __new__(cls, *args, **kwargs):
print("这是new方法中的cls",cls)
print("这是new方法")
def __init__(self):
print("这是init方法中的self",self)
p = Student()
# 这是new方法中的cls <class '__main__.Student'>
# 这是new方法
# __new__() 没有返回值的情况,不执行__init__()
class Student:
def __new__(cls, *args, **kwargs):
print("这是new方法中的cls",cls)
print("这是new方法")
# 调用父类的new方法,创建当前类的实例对象,返回对象的引用
return object.__new__(cls)
# 或者
return super.__new__(cls)
def __init__(self):
print("这是init方法中的self",self)
p = Student()
# 这是new方法中的cls <class '__main__.Student'>
# 这是new方法
# 这是init方法中的self <__main__.Student object at 0x000001DB681AE140>
# 单例模式
- 是一个特殊的类,这个类只能够创建一次实例对象,指向同一个内存地址
# 1、通过new方法实现
class A:
_ins = None
def __new__(cls, *args, **kwargs):
if cls._ins is None:
cls._ins = super().__new__(cls)
return cls._ins
a = A()
b = A()
print(a is b) # True
# 2、通过类方法方法实现
class A:
__ins = None
@classmethod
def get_instance(cls):
if not cls.__ins:
cls.__ins = object.__new__(cls)
return cls.__ins
a = A.get_instance()
b = A.get_instance()
print(a is b) # True
# 3、通过装饰器实现
def outer(func):
__ins = {}
def inner(*args, **kwargs):
if func not in __ins:
ret = func(*args, **kwargs)
__ins[func] = ret
else:
ret = __ins[func]
return inner
@outer
class A:
def __init__(self):
print("init")
a = A()
b = A()
print(a is b)
# 4、通过导入模块实现
class Test:
def eat(self):
pass
t1 = Test()
print(t1)
from test import Test
from test import Test
# 两次print(t1)的内存地址相同
# 5、通过元类实现
# hasattr()函数用于判断对象是否包含对应的属性
class A:
def __new__(cls, *args, **kwargs):
if not hasattr(cls, '_instance'):
cls._instance = super(A, cls).__new__(cls, *args, **kwargs)
return cls._instance
def __init__(self):
print("A")
a = A()
b = A()
print(a is b) # True
python的模块是天然的单例模式
因为第一次导入时会加载到内存空间,第二次及以后再导入只会引用而不会再次执行模块代码
# 魔术方法(内置的类方法)
# __init__ 构造方法
# __doc__ 查看函数的说明文档
# __str__ 将类装饰为字符串
def __str__(self):
return f"Student类对象,name={self.name},age={self.age},grade={self.grade}"
# __modules__ 当前操作的对象在哪个模块(读取模块名)
# __class__ 当前操作的对象的类是什么(读取类名)
from b1 import A
obj = A()
print(obj.__modules__) # b1
print(obj.__class__) # <class 'b1.A'>
# __dict__ 查看类或对象中的所有属性
A.__dict__
# __lt__ 小于、大于符号比较
def __lt__(self, other):
return self.age < other.age
stu1 = Student("张三", 20, 99)
stu2 = Student("李四", 30, 89)
print(stu1 < stu2) # True
# __le__小于等于、大于等于符号比较
def __le__(self, other):
return self.age <= other.age
stu1 = Student("张三", 20, 99)
stu2 = Student("李四", 30, 89)
print(stu1 <= stu2) # True
# __eq__ 等于符号比较
def __eq__(self, other):
return self.age == other.age
stu1 = Student("张三", 20, 99)
stu2 = Student("李四", 30, 89)
print(stu1 == stu2) # False
# 类型注解
# 类型注解的语法
为变量设置注解,显示的变量定义,一般无需注解
# 基础数据类型注解
var1:int = 10
var2:float = 21.56
var3:bool = True
var4:str = "张三"
# 类对象的注解
class student:
pass
stu:student = student()
# 基础容器类型注解
my_list:list = [1, 2, 3]
my_tuple:tuple = (1, 2, 3)
my_set:set = {1, 2, 3}
my_dict:dict = {"name": sylone}
# 容器类型详细注解
my_list:list[int] = [1, 2, 3]
my_tuple:tuple[str, int, bool] = ("sylone", 666, True)
my_set:set[int] = {1, 2, 3}
my_dict:dict[str, int] = {"sylone": 666}
# 函数(方法)的类型注解:形参注解,返回值注解
def func(name: str, age: int, grade: int) -> None:
pass
# 除了使用 变量:类型,这种语法做注解外,也可以在注释中进行类型注解
var1 = random.randint(l, 10) # type: int
var2 = json.loads(data) # type: dict[str, int]
var3 = student() # type: student
注意:类型注解的作用
- 帮助第三方IDE工具(如PyCharm)对代码进行类型推断,协助做代码提示
- 帮助开发者自身对变量进行类型注释
- 并不会真正的对类型做验证和判断,类型注解仅仅是提示性的
# 这样的代码,是不会报错的哦
var1:int = "itheima"
var2:str = 123
# Union联合类型注解
# 先导包
from typing import Union
my_list:list[Union[str, int]] = [1, 2, "itheima", "itcast"]
my_dict:dict[str, union[str, int]]={"name": "sylone", "age": 31}
def func(data: union[int, str]) -> union[int, str]:
pass
# 文件操作
# 打开文件
使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
# name 是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
# mode 设置打开文件的模式:只读、写入、追加等
# r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式
# w:打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除
# 如果该文件不存在,创建新文件
# a:打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后
# 如果该文件不存在,创建新文件进行写入
# encoding 编码格式(推荐使用UTF-8)
open(name, mode, encoding)
f = open("python.txt", "r", encoding="UTF-8")
# encoding的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定
# 读取操作
f.read(num)
# num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
f = open('python.txt')
content = f.read(10) # 读取10个字节
f.readline()
# 读取一行数据
line1 = f.readline()
line2 = f.readline()
print(f"第一行数据是:{line1}")
print(f"第二行数据是:{line2}")
f.readlines()
# 可以按照行的方式把文件中的内容进行一次性读取,返回的是一个list列表,其中每一行的数据为一个元素
f = open('python.txt')
content = f.readlines()
print(content)
# ['hello world\n', 'abcdefg\n', 'aaa\n', 'bbb\n', 'ccc']
f.close() # 关闭文件
# for循环读取文件行
for line in open("python.txt", "r"):
# 每一个line临时变量,就记录了文件的一行数据
print(line)
# 关闭文件对象
f = open("python.txt","r")
f.close()
# 最后通过close,关闭文件对象,也就是关闭对文件的占用
# 如果不调用close,同时程序没有停止运行,那么这个文件将一直被python程序占用
with open("python.txt", "r") as f:
f.readlines()
# 通过在with open的语句块中对文件进行操作
# 可以在操作完成后自动关闭close文件,避免遗忘掉close方法
# 写入操作
# 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
# 当调用flush的时候,内容会真正写入文件
# 这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
# 1.打开文件
f= open('python.txt', 'w')
# 2.文件写入
f.write('hello world')
# 3.内容刷新
f.flush()
# 4.或者close方法,内置了flush的功能
f.close()
url='http://www.1ge0.com/imgs/logo.jpg'
r=requests.get(url)
print(r.status_code) # 状态码 200
# 以二进制写入模式('wb')进行操作
with open('logo.jpg','wb') as f:
f.write(r.content) # 图片
# 追加写入操作
f= open('python.txt', 'a') # 文件不存在会创建文件
f.write('hello world')
f.flush()
# 或者close方法,内置了flush的功能
f.close()
# 综合案例
# 打开文件得到文件对象,准备读取
fr = open("D:/bill.txt", "r", encoding="UTF-8")
# 打开文件得到文件对象、准备写入
fw = open("D:/bill.txt.bak", "w", encoding="UTF-8")
# for循环读取文件
for line in fr:
line = line.strip()
# 判断内容,将满足的内容写出
if line.split(",")[4] == "测试":
continue # continue进入下一次循坏,这一次后面的内容就跳过了
# 将内容写出去
fw.write(line)
# 由于前面对内容进行了strip()的操作,所以要手动的写出换行符
fw.write("\n")
# close2个文件对象
fr.close()
# 写出文件调用close()会自动flush()
fw.close()
# 异常处理
# 异常处理
- 常规异常
try:
# 可能发生错误的代码
except:
# 如果出现异常执行的代码
- 捕获指定异常
try:
print(name)
except NameError as e:
print('name变量名称未定义错误')
- 捕获多个异常
try:
print(1/0)
# 使用元组的方式进行书写
except (NameError, ZeroDivisionError):
print('ZeroDivision错误...')
- 捕获所有异常
try:
f= open("D:/123.txt","r")
except Exception as e:
print("出现异常了")
- 异常 else
try:
print(1)
except Exception as e:
print(e)
else:
print("我是else,是没有异常的时候执行的代码")
- 异常 finally 表示的是无论是否异常都要执行的代码
try:
f = open('test.txt', 'r')
except Exception as e:
f = open('test.txt', 'w')
else:
print('没有异常,真开心')
finally:
f.close()
# 抛出异常
# 创建一个Exception(’...’)的对象
# raise 抛出这个对象
def func():
raise Exception('异常信息')
print("是的")
func()
# 模块的介绍
模块 Module,是一个 Python 文件,以.py 结尾,模块能定义函数、类和变量,也能包含可执行的代码
# 模块的导入方式
[from 模块名] import [模块 | 类 | 变量 | 函数 | * ] [as 别名]
# 常用的组合形式
- import 模块名
# 导入时间模块
import time
print("开始")
# 让程序睡眠1秒(阻塞)
time.sleep(1)
print("结束")
- from 模块名 import 功能名
# 导入时间模块中的sleep方法
from time import sleep
print("开始")
# 让程序睡眠1秒(阻塞)
sleep(1)
print("结束")
- as 定义别名
# 模块别名
import time as tt
tt.sleep(2)
print('hello")
# 功能别名
from time import sleep as sl
sl(2)
print('hello")
# 常用变量
- main
def test(a, b):
print(a + b)
# PyCharm 中右键运行的时候__name__=='__main__'
if __name__ == '__main__':
test(1, 2)
- all
# 通过在模块文件中设置 __all__ 变量,当其它文件以 from 模块名 import * 的形式导入该模块时
# 该文件中只能使用 __all__ 列表中指定的成员
# __init__.py 中
__all__ = ["test"]
def test():
print('----test-----')
def test1():
print('----test1----')
# 当包作为模块导入时,包目录下会生成一个__pycache__文件夹
# main.py
from test1 import *
def main():
test()
#test1()
main()
# 内置模块
- os 模块
# 读取环境变量path的信息
os.getenv('path')
# 调用系统命令
os.system("chcp 65001") # 防止乱码
os.system("cmd")
os.system("regedit.exe")
os.system("ping www.baidu.com")
os.system("calc.exe") # 调用系统可执行文件
os.system(r"C:\Users\Administrator\AppData\Local\CSViewer\CSViewer.exe") # 调用用户可执行文件
# 文件目录操作
os.sep # 系统的路径分隔符,Windows 系统:使用反斜杠 \,Linux:使用正斜杠 /
os.getcwd() # 获取当前工作目录
os.chdir(r'c:\users\Admin\Desktop\demo') # 改变工作目录
os.mkdir('test') # 创建目录
os.rmdir('test') # 删除目录
os.makedirs('a/b/c') # 创建多级目录
os.removedirs('a/b/c') # 删除的时候,需要保证目录是空的
os.rename(r'c:\Users\Admin\Desktop\demo',r'c:\Users\Admin\Desktop\test') # 重命名
os.listdir() # 返回指定的文件夹包含的文件夹或者文件的名字的列表
# 文件操作
os.path.dirname(r'D:\Java\nginx-1.9.9.zip') # 获得目录
os.path.basename(r'D:\Java\nginx-1.9.9.zip') # 返回文件名
os.path.abspath('./') # 返回当前路径的绝对路径
os.path.abspath('../') # 返回上层路径的绝对路径
os.path.exists(r'D:\Java\nginx-1.9.9.zip') # 判断路径是否存在
os.path.isabs(r'D:\Java\nginx-1.9.9.zip') # 判断是否是绝对路径
os.path.isfile(r'D:\Java\nginx-1.9.9.zip') # 判断一个文件是否存在
os.path.isdir(r'D:\Java') # 判断一个文件夹是否存在
os.path.getsize('d:/a.txt') # 文件大小
os.path.getctime('d:/a.txt') # 返回创建时同
os.path.getatime('d:/a.txt') # 返回最近访间时间
os.path.getmtime('d:/a.txt') # 返回文件的最近修改时间
os.path.split(r'D:\Java\nginx.zip') # ('D:\\Java','nginx.zip')一个是目录,一个是文件名
os.path.splitext(r'D:\Java\nginx.zip') # ('D:\\Java\\nginx','.zip')一个是目录,一个是后缀名
os.path.join('a','b','c','1.txt') # a\b\c\1.txt
# os.walk 遍历
path = os.getcwd()
files_tuple = os.walk(path)
# root是当前目录,dirs是当前目录下的所有目录,files是当前目录下的所有文件
for root, dirs, files in files_tuple:
for file in files:
if file.endswith(".py"):
print(file)
shutil.copyfile(r'1.txt',r'2.txt') # 复制文件内容
# 复制文件夹,包括子目录,目标目录必须不存在
shutil.copytree(r'F:\VUE\Blog',r'F:\VUE\01',ignore=shutil.ignore_patterns('*.txt'))
shutil.make_archive(r'F:\VUE\Blog\01','zip',r'F:\VUE\Blog\01') # 压缩文件
shutil.unpack_archive(r'F:\VUE\Blog\01.zip',r'F:\VUE\Blog\01') # 解压文件
shutil.rmtree(r'F:\VUE\Blog\01') # 删除文件夹
# 压缩
z1= zipfile.ZipFile('a.zip','w')
z1.write('1.txt')
z1.write('2.txt')
z1.close()
# 解压
z2= zipfile.ZipFile('a.zip','r')
z2.extractall()
z2.close()
- sys 模块
sys.getdefaultencoding() # 获取系统当前编码
sys.path # 获取使用PYTHONPATH环境变量的值
sys.platform # 获取当前系统平台名称
sys.version # 获取Python解释程序的版本信息
- time 模块
time.time() # 获取时间戳 1740917414.0492156
time.localtime() # 获取本地时间 time.struct_time(tm_year=2022, tm_mon=8, tm_mday=13, tm_hour=10, tm_min=57, tm_sec=14, tm_wday=3, tm_yday=223, tm_isdst=0)
time.asctime() # 获取本地时间字符串 Sun Mar 2 20:11:04 2025
time.strftime('%Y-%m-%d',time.localtime()) # 格式化时间字符串
time.strptime('2025-05-20 12:12:25','%Y-%m-%d %H:%M:%S') # 将格式字符串转化成struct_time
- logging 模块
DEBUG # 调试
INFO # 信息
WARNING # 警告
ERROR # 错误
CRITLCAL # 危险信号
import logging
# 简单使用
formatLog = '日志时间:%(asctime)s - 日志级别:%(levelname)s - 日志内容:%(message)s'
logging.basicConfig(format=formatLog, filename=r'D:\test.log', level=logging.DEBUG)
logging.debug('This message should go to the log file')
# 日志管理器的使用
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# 处理器
sh = logging.StreamHandler() # 控制台输出
sh.setLevel(logging.DEBUG)
fh = logging.FileHandler(r'D:\test.log',encoding='utf-8') # 文件输出
fh.setLevel(logging.ERROR)
# 格式器
formatter = logging.Formatter(formatLog)
sh.setFormatter(formatter)
fh.setFormatter(formatter)
# 日志器添加处理器
logger.addHandler(sh)
logger.addHandler(fh)
# 日志器输出
logger.debug('This message should go to the log file')
logger.info('So should this')
logger.warning('And this, too')
# 包文件的介绍
包就是一个文件夹,在该文件夹下包含了一个 _ init _.py 文件,该文件夹可用于包含多个模块文件
# 在项目根目录右击-> New -> Python Package -> 输入包名称 -> 点击OK
# 新建包后,包内部会自动创建 _init_.py 文件
# 导入包
- 方式一
# import 包名.模块名
# 包名.模块名.目标
import my_package.my_module1
import my_package.my_module2
# 包中的my_module1模块的info_print1()方法
my_package.my_module1.info_print1()
# 包中的mymodule2模块的info_print2()方法
my_package.my_module2.info_print2()
- 方式二
# 注意: 必须在 _init_.py 文件中添加 _all_=[] 控制允许导入的模块列表
# _init_.py
all = ["my_module2"]
# text_my_module.py
from my_package import *
# 包中的my_module1模块的info_print1()方法
my_modulel.info_print1() # 报错
# 包中的mymodule1模块的info_print2()方法
my_module2.info_print2()
# 正则表达式
# match() 方法的基本使用
- 从字符串的起始位置匹配一个正则表达式,如果起始位置匹配不成功,返回None
- 如果匹配到了数据,使用group方法来提取数据
import re
res = re.match('S', 'six')
print(res.group()) # 匹配失败 返回 None
res = re.match('s', 'six')
print(res.group()) # 匹配成功 返回 s
- 匹配单个字符
. # 匹配任意1个字符(除了\n)
[] # 匹配[ ]中列举的一个字符
\d # 匹配数字,即0-9
\D # 匹配非数字,即不是数字
\s # 匹配空白,即空格,tab键
\S # 匹配非空白
\w # 匹配非特殊字符,即a-z,A-Z,0-9,_,汉字
\W # 匹配特殊字符
# 匹配任意1个字符
res = re.match('t.o', 'too')
print(res.group()) # too
# 匹配[ ]中列举的一个字符
res = re.match('[hH]', 'hello')
print(res.group()) # h
res = re.match('^ab','abs') # 匹配开头
print(res.group())
res = re.match('[0123456789]hello','1hello')
print(res.group()) # 1hello
res = re.match('[0123456789]h2ello','1hello')
print(res.group()) # 匹配失败 返回 None
res = re.match('[0-9]hello','1hello')
print(res.group()) # 1hello
res = re.match('[0-35-9]hello','1hello') # 匹配0-9但不匹配4
print(res.group()) # 1hello
# 匹配数字,即0-9
res = re.match('今天是2\d号','今天是21号了吗')
print(res.group()) # 今天是21号
# 匹配空白,即空格,tab键
res = re.match('\sh',' hello python')
print(res.group()) # 空白h
res = re.match('\S','hello python')
print(res.group()) # h
# 匹配非特殊字符
res = re.match('\w','hello python')
print(res.group()) # h
- 匹配多个字符
* # 匹配前一个字符出现0次或者无数次,即可有可无
+ # 匹配前一个字符出现1次或者无数次,即至少有1次
? # 匹配前一个字符出现1次或者0次,即最多1次
{m} # 匹配前一个字符出现m次
{m,n} # 匹配前一个字符出现m到n次
# 匹配前一个字符出现0次或者无数次,即可有可无
res = re.match('[A-Z][a-z]*','Hello python')
print(res.group()) # Hello
res = re.match('[a-z]*python[a-z]*','hellopythonaaa')
print(res.group()) # hellopythonaaa
# 匹配前一个字符出现1次或者无数次,即至少有1次
res = re.match('[a-zA-Z]+python','hellopython')
print(res.group()) # hellopython
# 匹配前一个字符出现1次或者0次,即要么有1次要么没有
res = re.match('[1-9]?[0-9]','1234')
print(res.group()) # 12
res = re.match('[1-9]?\d','1234')
print(res.group()) # 12
# 匹配前一个字符出现m次
res = re.match('[0-9]{6}','123456789')
print(res.group()) # 123456
res = re.match('[a-zA-Z0-9_]{6,8}','a12345678')
print(res.group()) # a1234567
- 匹配开头和结尾
^ # 匹配字符串开头
$ # 匹配字符串结尾,匹配的字符串必须符合正则表达式的要求位数
[^指定字符] # 除了指定字符外都匹配
res = re.match('^[0-9]','1abs') # 匹配数字开头
print(res.group()) # 1
res = re.match('[^0-9]','abs') # 匹配非数字开头
print(res.group()) # a
res = re.match('[1-9]?\d$', '10') # 匹配数字结尾
print(res.group()) # 10
res = re.match('^[0-9]{3}\-[0-9]{3,8}$', '010-12345')
print(res.group()) # 提取数据 010-12345
- 匹配分组
| # 匹配左右任意一个表达式
(ab) # 将括号中的字符作为一个分组
\num # 引用分组 num 匹配到的字符串
(?P<name>) # 分组起别名
(?P=name) # 引用别名为name分组匹配到的字符串
# 将括号中的字符作为一个分组
res = re.match('\w{4,20}@(163|qq|139).com', 'test@163.com')
print(res.group()) # 匹配全部内容:test@163.com
print(res.group(0)) # 匹配全部内容:test@163.com
print(res.group(1)) # 匹配第1个分组的内容:163
# 引用分组 num 匹配到的字符串
res = re.match('<(\w*)>\w*</\\1>', '<html>title</html>') # \1 代表引用第一个分组的内容
# \转义符 用\转义一下,来表示引用。否则会认为是普通字符,在字符串里原样输出
print(res.group()) # <html>title</html>
# 或者用 r 原样输出
res = re.match(r'<(\w*)>\w*</\1>', '<html>title</html>')
# 分组起别名
# ?P<n1>是给分组起名字 ?P=n1是引用分组
res = re.match('<(?P<n1>\w*)><(?P<n2>\w*)>.*</(?P=n2)></(?P=n1)>', '<h1><a>hello</a></h1>')
print(res.group()) # <h1><a>hello</a></h1>
# 高级用法
- search() 扫描整个字符串并返回第一个成功的匹配,match() 只能从开始位置匹配
res = re.search('\d+', '我今年18岁,明年19岁')
print(res.group()) # 18
res = re.match('ab', '12abc')
print(res.group()) # 返回none 报错
res = re.search('ab', '12abc')
print(res.group()) # ab
- findall() 以列表的形式返回匹配到的字符串,直接打印结果
res = re.findall('\d+', '我今年18岁,明年19岁')
print(res) # ['18', '19']
res = re.findall('[^\d+]', '我今年18岁,明年19岁')
print(res) # ['我', '今', '年', '岁', ',', '明', '年', '岁']
- sub() 将匹配到的数据进行替换
res = re.sub('\d+','60', '我今年18岁,明年19岁')
print(res) # 我今年60岁,明年60岁
# count 替换的次数
res = re.sub('\D+','60', '我今年18岁,明年19岁', count=2)
print(res) # 6018601960
- split() 根据匹配进行切割字符串,并返回一个列表
res = re.split(':| ','a b:c d') # 按冒号或空格切分
print(res) # ['a', 'b', 'c', 'd']
res = re.split('[:, ]','a b:c d') # 按冒号或空格切分
print(res) # ['a', 'b', 'c', 'd']
res = re.split('[:, ]','a b:c d',2) # 切2次
print(res) # ['a', 'b', 'c d']
- 贪婪匹配和非贪婪匹配
# 贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
# 非贪婪匹配:在满足匹配时,匹配尽可能短的字符串,使用 ? 来表示非贪婪匹配
res = re.match('ab*','abbbc')
print(res.group()) # abbb
res = re.match('ab*?','abbbc')
print(res.group()) # a
res = re.findall('<.*>','<h1>hello</h1>')
print(res) # ['<h1>hello</h1>']
res = re.findall('<.*?>','<h1>hello</h1>')
print(res) # ['<h1>', '</h1>']
# 线程的使用
# 线程的基础用法
使用 threading 模块里的 Thread 类创建出实例对象,然后通过 start() 方法产生一个新的线程
- 程序启动默认会有一个主线程
- 通过 start() 方法来启动子线程
- 线程之间执行是无序的,它是由cpu调用来决定的
- 通过 name 属性设置线程名称
- 通过 is_alive 获取线程运行状态
import time
import threading
start = time.time()
def dance(name):
print('%s 跳舞' % name)
time.sleep(1)
if __name__ == '__main__':
for i in range(5):
# 创建线程,arcgs是元组,元组中只有一个元素,需要在元素后加逗号
t = threading.Thread(target=dance, args=('t-%s' % i,))
# 设置线程名字
t.name = '111'
# 获取线程名字
print(t.name)
# 获取线程运行状态
print(t1.is_alive())
print(t2.is_alive())
# 启动线程
t.start()
end = time.time()
print(end - start)
注意
threading.Thread(target=dance('t-%s' % i)) 如果这样 dance 加了括号,就是调用了这个函数,而这个函数没有return,就是返回none,target=none
- 守护线程 daemon:主线程结束,子线程也结束,不会等待子线程执行完成
- 阻塞线程 join:主线程等待子线程执行完再执行
import time
from threading import Thread
def dance(name):
print('%s 跳舞前\n' % name)
time.sleep(5)
print('%s 跳舞后\n' % name)
def sing(name):
print('%s 唱歌前\n' % name)
time.sleep(5)
print('%s 唱歌后\n' % name)
if __name__ == '__main__':
t1 = Thread(target=dance,args=('张三',))
t2 = Thread(target=sing,args=('李四',))
# 设置守护线程
t1.daemon = True
t2.daemon = True
t1.start()
t2.start()
print('主线程结束')
# 输出
# 张三 跳舞前
# 李四 唱歌前
# 主线程结束
# 阻塞线程,主线程等待t1、t2执行完再执行
t1.join()
t2.join()
print('主线程结束')
# 张三 跳舞前
# 李四 唱歌前
# 李四 唱歌后
# 张三 跳舞后
# 主线程结束
- 线程执行代码封装,默认按顺序执行
import time
from threading import Thread
# 定义一个新类集成Thread
class MyThread(Thread):
def run(self):
print("子线程开始\n")
time.sleep(2)
print("子线程结束\n")
if __name__ == "__main__":
t = MyThread()
t.start()
print("主线程开始")
# 输出
# 子线程开始
# 主线程开始
# 子线程结束
- run 与 start 方法的区别
start方法 # 是声明分到一个子线程的函数已经就绪,等待被CPU执行
run方法 # 是执行到这个子线程时,自动调用的方法
import threading
from threading import Thread
# 定义一个新类集成Thread
class MyThread(Thread):
def run(self):
print(f'当前线程名称:{threading.current_thread().name}')
if __name__ == "__main__":
t = MyThread()
t.start()
t.run()
# 输出
# 当前线程名称:Thread-1
# 当前线程名称:MainThread
# 局部变量和全局变量
- 对于函数的局部变量,局部变量是每个线程独有的资源,不会产生冲突的,每个线程都会有局部变量的拷贝
import threading
from time import sleep
def thread_entry():
var = 1
for i in range(10):
# 获得当前线程对象,ident表示线程的id号
print('th #{} :{}'.format(threading.current_thread().ident, var))
sleep(1)
var += 1
if __name__ == '__main__':
print('main thread start.')
t1 = threading.Thread(target=thread_entry)
t2 = threading.Thread(target=thread_entry)
t1.start()
t2.start()
print('main thread end.')
- 全局变量是共享的,是会产生冲突,要控制
from threading import Thread
a = 0
b = 1000000
def sum1():
for i in range(b):
global a
print(a)
a += 1
print(f"第一次:{a}\n",end="")
def sum2():
for i in range(b):
global a
print(a)
a += 1
print(f"第二次:{a}\n",end="")
if __name__ == "__main__":
t1 = Thread(target=sum1)
t2 = Thread(target=sum2)
t1.start()
t2.start()
# 输出
# 第一次:1987150
# 第二次:2000000
- 解决资源竞争的两个办法:
# 线程等待 join
# 互斥锁:对共享数据进程锁定,保证同一时刻只能有一个线程操作
# 互斥锁的创建流程
# 1、定义互斥锁
# 2、acquire 加锁
# 3、release 释放锁
import threading
from threading import Thread
a = 0
b = 1000000
# 创建全局互斥锁
lock = threading.Lock()
def sum1():
lock.acquire()
for i in range(b):
global a
a += 1
print(f"第一次:{a}\n",end="")
lock.release()
def sum2():
lock.acquire()
for i in range(b):
global a
a += 1
print(f"第二次:{a}\n",end="")
lock.release()
if __name__ == "__main__":
t1 = Thread(target=sum1)
t2 = Thread(target=sum2)
t1.start()
t2.start()
# 输出
# 第一次:1000000
# 第二次:2000000
- 信号量是允许同一时间同时几个线程访问共享变量
import threading,time
# 锁 --- 信号量
sem = threading.BoundedSemaphore(3)
def foo(i):
# 上锁
sem.acquire()
time.sleep(1)
print(str(i)+'\n')
# 解锁
sem.release()
for i in range(10):
t = threading.Thread(target=foo,args=(i,))
t.start()
# 输出
# 2 1 0 4 5 3 8 7 6 9
# 生产者消费者
import threading,time
from random import randint
# 存放共享资源的 列表
commandList =[]
# 创建锁对象
cv = threading.Lock()
# 生产者线程
def thread_producer():
global commandList
cmdNo = 0
while True:
cmdNo += 1
# 这里生产的资源,就先用一个字符串来表示
resource = 'command_{cmdNo}'
# 随机等待一段时间,表示 生产资源的时间,就是输入命令耗费的时间
# 其中参数a是下限,参数b是上限,生成的随机数n:a<=n<=b
time.sleep(randint(3,3))
# 生产好了后,先申请锁
cv.acquire()
#申请锁成功后, 资源 存放入 commandList (共享对象)中
commandList.append(resource)
print('produce resource %s' % resource)
# 释放锁
cv.release()
# 消费者线程,
def thread_consumer ():
global commandList
while True:
# 先申请锁
cv.acquire()
resource = None
# 拿出 生产者线程 产生的一个资源,也就是一个命令
if commandList:
# 表示,已经被本消费者取出该资源了
resource = commandList.pop(0)
# 取出一个共享资源后释放锁(生产者线程就可以对共享资源进行操作了)
cv.release()
if resource != None:
# 随机等待一段时间,表示 消费资源的时间
time.sleep(randint(1, 3))
print('consume resource %s' % resource)
# 注意上面的代码,当commandList里面没有 命令的时候
# 就会不停的执行空循环,非常耗CPU资源
if __name__=='__main__':
t1 = threading.Thread(target=thread_producer)
t2 = threading.Thread(target=thread_consumer)
t1.start()
t2.start()
t1.join()
t2.join()
- 设置条件变量
import threading,time
from random import randint
commandList =[]
# 调用 Condition,返回一个条件对象, 该对象包含了一个锁对象
cv = threading.Condition()
# 消费者线程
def thread_consumer ():
global commandList
while True:
# 先申请锁,条件变量中包含了锁,可以调用acquire
cv.acquire()
# 如果命令表为空 调用条件变量wait方法 ,该调用会释放锁,并且阻塞在此处,
# 直到生产者 生产出资源后,调用 该条件变量的notify , 唤醒 自己
# 一旦被唤醒, 将重新获取锁(所以生产者线程此时不能对共享资源进行操作)
while commandList == []:
cv.wait()
resource = None
# 拿出 生产者线程 产生的一个资源
if commandList:
# 表示,已经被本消费者取出该资源了
resource = commandList.pop(0)
# 取出一个共享资源后释放锁(生产者线程就可以对共享资源进行操作了)
cv.release()
if resource != None:
# 随机等待一段时间,表示 消费资源的时间
time.sleep(randint(1, 3))
print('consume resource %s' % resource)
# 生产者线程
def thread_producer():
global commandList
cmdNo = 0
while True:
cmdNo += 1
# 这里生产的资源,就先用一个字符串来表示
resource = 'command_{cmdNo}'
# 随机等待一段时间,表示生产资源的时间
time.sleep(randint(3,3))
# 通过条件变量 先申请锁
cv.acquire()
#申请锁成功后, 资源 存放入commandList 中
commandList.append(resource)
print('produce resource %s' % resource)
# 随后调用notify,就像说 有任务啦,等任务的线程来处理吧。。
# 该调用会唤醒一个 阻塞在该条件变量上等待的消费者线程
cv.notify()
# 当然也要释放一下condition里面的锁
cv.release()
if __name__=='__main__':
t1 = threading.Thread(target=thread_producer)
t2 = threading.Thread(target=thread_consumer)
t1.start()
t2.start()
t1.join()
t2.join()
# 进程的使用
# 进程的基础用法
Process类的参数说明
# target 表示调用对象,即子进程执行的任务
# args 给target指定的函数传递的参数,元组的方式传递
# kwargs 表示调用字典对象
# name 子进程名称
# group 指定进程组
常用属性:
name # 当前进程的别名,默认Process-N,N从1开始递增的整数
pid # 进程号
ppid # 父进程号
import os
os.getpid() # 查看当前进程
os.getppid() # 查看当前进程父进程
进程常用的方法
start() # 启动进程实例
is_alive() # 判断子进程是否还活着,存活返回True或False
join([timeout]) # 是否等待子进程执行结束(在当前位置阻塞主进程),主进程等待子进程多长时间timeout
terminate() # 不管任务是否完成,立即终止子进程
注意
进程间不同享全局变量,进程间相对独立
from multiprocessing import Process
import os, time
def proc1_entry(name):
print('子进程 1: %s (%s)...' % (name, os.getpid()))
time.sleep(2)
def proc2_entry(name):
print('子进程 2: %s (%s)...' % (name, os.getpid()))
time.sleep(2)
if __name__ == '__main__':
# 主进程的父进程是PyCharm的ID
print('主进程 %s...主进程的父进程 %s ' % (os.getpid(), os.getppid()))
p1 = Process(target=proc1_entry, args=('p1',))
p2 = Process(target=proc2_entry, args=('p2',))
p1.start()
p2.start()
p1.join()
p2.join()
print('主进程结束')
# 输出
# 主进程 8064...主进程的父进程 3748
# 子进程 1: p1 (1848)...
# 子进程 2: p2 (5480)...
# 2秒后
# 主进程结束
- 进程间的通信,本质是共享的消息队列
# 支持队尾插入元素,队头删除元素
# 可以使用 multiprocessing 模块的 Queue 实现多进程之间的数据传递,Queue本身是一个消息列队程序
q.empty() # 是否为空
q.full() # 是否满了
q.put() # 放入数据
q.get() # 取出数据
q.qsize() # 查看消息数量
q.maxsize # 队列中存放数据的上限(整数)一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉
# maxsize<=0队列大小没有限制
from multiprocessing import Queue
# 初始化一个Queue对象,最多可接收三条消息
q = Queue(3)
q.put("Message 1")
q.put("Message 2")
print(q.full()) # False
q.put("Message 3")
print(q.full()) # True
# 因为消息队列已满,下面的try会等待2秒后再抛出异常
try:
# True是block值,消息队列没空间写入时,程序进入阻塞状态
# 2是timeout值,等待超时时间,阻塞时间超过2秒后,抛出异常
q.put("Message 4", True, 2)
except:
print("消息队列已满,现有消息数量:%s" %q.qsize())
# 会立刻抛出异常
try:
q.put_nowait("Message 4")
except:
print("消息队列已满,现有消息数量:%s" %q.qsize())
from multiprocessing import Queue, Process
import time
list1 = [1, 2, 3, 4, 5]
def write(q):
for i in list1:
print("正在写入:", i)
q.put(i)
time.sleep(2)
def read(q):
while True:
if not q.empty():
value = q.get(True)
print("正在读取:", value)
time.sleep(1)
else:
break
if __name__ == '__main__':
q = Queue(10) # 初始化一个Queue对象,最多可接收10条put消息
p1 = Process(target=write, args=(q,)) # 写入进程
p2 = Process(target=read, args=(q,)) # 读取进程
p1.start()
p1.join()
p2.start()
# 输出
# 正在写入: 1
# 正在写入: 2
# 正在写入: 3
# 正在写入: 4
# 正在写入: 5
# 正在读取: 1
# 正在读取: 2
# 正在读取: 3
# 正在读取: 4
# 正在读取: 5
# 进程池
# 主要方法
p.apply_async() # 非阻塞方式调用 func 并行执行
p.apply() # 阻塞方式调用 func 并行执行,即同步
p.close() # 关闭进程池,防止进一步操作(进程池不接收新的任务)
p.join() # 阻塞
p.enumerate() # 不管任务是否完成,立即终止
from multiprocessing import Pool
import time
def learn(n):
print("learning %s" % n)
time.sleep(2)
return n**2
if __name__ == '__main__':
p = Pool(2) # 创建进程池,进程池中最大有3个进程一起执行
res_l = []
for i in range(5):
res = p.apply_async(learn, args=(i,)) # 异步提交任务
res_l.append(res)
p.close() # 关闭进程池,不再接收新的请求
p.join() # 等待进程池中所有的子进程执行完毕,必须放在close后面
for res in res_l:
print(res.get()) # 从进程池中获取结果,必须放在join后面
# 输出
# learning 0
# learning 1
# learning 2
# learning 3
# learning 4
# 0
# 1
# 4
# 9
# 16
- 进程池通信
# 需要使用 multiprocessing.Manager() 中 Queue()
# Manager()模块 专门做数据共享
# multiprocessing 模块下的 Queue 为进程提供通信服务
# Manager 模块下的 Queue 为线程提供通信服务
from multiprocessing import Pool,Manager
import os
def rd(q):
print(f'rd:{os.getpid()},father:{os.getppid()}')
for i in range(q.qsize()):
print(f'rd:{q.get()}')
def wr(q):
print(f'wr:{os.getpid()},father:{os.getppid()}')
for i in '123':
print(f'wr:{i}')
q.put(i)
if __name__ == '__main__':
print(f'main:{os.getpid()},father:{os.getppid()}')
# 实例化进程池队列对象
q = Manager().Queue()
# 实例化进程池对象
p = Pool()
p.apply_async(wr,args=(q,))
p.apply_async(rd,args=(q,))
p.close()
p.join() # 阻塞主进程
print(f'end {os.getpid()}')
# 输出
# main:6392,father:2520
# wr:4348,father:6392
# wr:1
# wr:2
# wr:3
# rd:6364,father:6392
# rd:1
# rd:2
# rd:3
# end 6392
# 协程的使用
# 生成器 yield
- 生成器函数可以在运行中暂停并返回一个中间结果,下一次调用时,可以从上一次暂停的位置开始执行
- yield语句类似于return语句,但不同之处在于,它可以多次返回一个中间结果,并保留函数的状态
# 使用yield语句定义生成器函数,生成数字1、2、3和4
def my_generator():
yield 1
yield 2
yield 3
yield 4
# 通过调用next()函数来迭代生成器
g = my_generator()
print(next(g)) # 输出 1
print(next(g)) # 输出 2
print(next(g)) # 输出 3
print(next(g)) # 输出 4
# 还可以使用for循环对生成器进行迭代
for i in my_generator():
print(i)
import time
def fun1():
a = 1
print("将a赋值")
yield a #中断函数,返回return a,等待写一个next才会执行
b = 2
print("将b赋值")
yield b
pass
def main():
g1 = fun1()
print(next(g1))
time.sleep(2)
print(next(g1))
pass
if __name__=='__main__':
main()
# 输出
# 将a赋值
# 1
# 将b赋值
# 2
# 协程的基本介绍
# 协程:单线程下的开发,又称微线程,可以在单个线程中实现多个并发任务
# 协程看着也是子程序,但执行过程中,在子程序内部可中断,转而执行别的子程序,适当的时候再返回来执行
# 注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断
# 应用场景:IO特别多,可以避免多线程的上下文切换开销,提高程序的效率
import time
def task1():
while True:
print("---任务1---")
time.sleep(1)
yield
def task2():
while True:
print("---任务2---")
time.sleep(2)
yield
def main():
t1 = task1()
t2 = task2()
while True:
next(t1)
next(t2)
pass
if __name__=='__main__':
main()
# 输出
# ---任务1---
# ----任务2---
# ----任务1---
# ----任务2---
# ----任务1---
# ----任务2---
# ----任务1---
# ----任务2---
#无限下去。。。。
# greenlet 模块
greenlet 实现了轻量级的协程,通过调用 switch() 方法,可以从当前协程中切换到指定的协程上下文,从而实现协程之间的切换
from greenlet import greenlet
def main():
def eat(name1,name2):
print("%s eat 1" % name1)
g2.switch("haha")
print("%s eat 2" % name2)
g2.switch()
def play(name):
print("%s play 1" % name)
g1.switch()
print("%s play 2" % name)
g1 = greenlet(eat)
g2 = greenlet(play)
g1.switch("hehe","heihei")
pass
if __name__=='__main__':
main()
# 输出
# hehe eat 1
# haha play 1
# heihei eat 2
# haha play 2
# gevent 模块
# 可以自动切换协程
# gevent.spawn() 创建协程对象
# gevent.sleep(1) 用来模拟一个耗时操作,注意不是time模块中的sleep
# join()阻塞,直到这个协程执行完毕
import gevent
def eat(name):
print("%s eat 1"%name)
gevent.sleep(2) #模拟拥塞
print("%s eat 2"%name)
def play(name):
print("%s play 1"%name)
gevent.sleep(1)
print("%s eat 2"%name)
def main():
g1 = gevent.spawn(eat,"小明") #创建协程对象
g2 = gevent.spawn(play,"小红")
g1.join()
g2.join()
print("主")
pass
if __name__=='__main__':
main()
# 输出
# 小明 eat 1
# 小红 play 1
# 小红 eat 2
# 小明 eat 2
# 主
- joinall()方法的参数是一个协程对象列表,它会等待所有协程都执行完毕后再退出
import gevent
def task(name):
for i in range(3):
print(f'函数名是:{name},执行次数是:{i}')
gevent.sleep(1)
if __name__ == '__main__':
g1 = gevent.spawn(task, 'task1')
g2 = gevent.spawn(task, 'task2')
gevent.joinall([g1, g2])
# 输出
# 函数名是:task1,执行次数是:0
# 函数名是:task2,执行次数是:0
# 函数名是:task1,执行次数是:1
# 函数名是:task2,执行次数是:1
# 函数名是:task1,执行次数是:2
# 函数名是:task2,执行次数是:2
# 网络编程
Python中内置了一个socket模块,可以快速实现网络之间进行传输数据
# 实现服务端
import socket
# 1.监听本机的IP和端口
# 创建一个TCP套接字
# socket.socket()用于创建一个套接字对象。
# socket.AF_INET:这是地址族(Address Family)的一种,表示IPv4地址族
# socket.SOCK_STREAM:这是套接字类型,表示套接字使用面向连接的TCP协议
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('127.0.0.1', 8000)) # IP,端口
sock.listen(10) # 支持排队等待10人
while True:
# 2.等待,有人来连接(阻塞)
conn, addr = sock.accept() # 等待客户端来连接(阻塞)
# 3.等待,连接者发送消息(阻塞)
client_data = conn.recv(1024) # 等待接收客户端发来数据
print(client_data.decode('utf-8')) # 字节
# 4.给连接者回复消息
conn.sendall("hello world".encode('utf-8'))
# 5.关闭连接
conn.close()
# 6.停止服务端程序
sock.close()
# 实现客户端
import socket
# 1. 向指定IP发送连接请求
client = socket.socket()
client.connect(('123.206.15.88', 8000)) # 向服务端发起连接(阻塞)10s
# 2. 连接成功之后,发送消息
client.sendall('hello,world'.encode('utf-8'))
# 3. 等待,消息的回复(阻塞)
reply = client.recv(1024)
print(reply)
# 4. 关闭连接
client.close()
# 网络爬虫
# 基础请求
response.text # str类型,自动根据http头部对响应的编码作出推测,可以通过response.encodinpg设置
response.content # bytes类型,可以通过decode()解码
import requests
# 获取文字内容
url='https://www.baidu.com/'
response=requests.get(url)
response.encodinpg='utf-8' # 设置编码格式
print(response.status_code) # 状态码 200
print(response.text) # 网页源码
print(response.content.decode('utf-8')) # 网页源码
# 读取内容输入到文本
with open('baidu.txt','w', encoding='utf-8') as f:
f.write(response.content.decode('utf-8'))
# 获取图片内容
url='http://www.1ge0.com/imgs/logo.jpg'
response=requests.get(url)
with open('baidu.txt','wb') as f:
f.write(response.content) # 图片
# 带上 user-agent 发送请求
url='http://www.baidu.com'
# 第一种直接定义请求头
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
# 第二种定义多个请求头
UAlist=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
]
ua = random.choice(UAlist)
headers={
'User-Agent':ua
}
# 第三种方法,使用fake_useragent模块
from fake_useragent import UserAgent
ua = UserAgent().random
headers={
'User-Agent':ua
}
# 带上请求头
response=requests.get(url,headers=headers)
print(response.request.headers) # 打印请求头
print(response.content.decode()) # 打印响应体
# url 传参
from urllib.parse import quote,unquote
print(quote('你好')) # 明文转码
print(unquote('%E4%BD%A0%E5%A5%BD')) # 解码
url='http://www.baidu.com/s?'
ua = UserAgent().random
headers={
'User-Agent':ua
}
# 请求参数
kw = {'wd': 'python'}
# 带上请求头
response=requests.get(url,headers=headers,params=kw)
print(response.content.decode())
# cookie 的使用
url='http://www.baidu.com'
ua = UserAgent().random
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Cookie': 'BAIDUID=4253081149544622520:FG=1'
}
# 带上请求头
response=requests.get(url,headers=headers)
print(response.content.decode())
# post 请求
url='http://www.baidu.com'
ua = UserAgent().random
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
}
post_data={
'wd':'python'
}
# post 请求
response=requests.get(url,headers=headers,data=post_data)
print(response.content.decode())
# session 的使用
requests模块中的Session类能够自动处理发送请求获取响应过程中产生的cookie,进而达到状态保持的目的。
url='http://www.baidu.com'
session=requests.session() #创建一个session对象
session.post(url,data={'kw':'python'}) #发送一个post请求
session.get(url) #发送一个get请求
# 代理的使用
代理是一个IP,指向的是一个代理服务器,代理IP无效的花会使用本机IP,免费代理 (opens new window)
正向代理 # 保护客户端,让服务器不知道客户端的真实身份
反向代理 # 保护服务器端,让浏览器不知道服务器的真实地址
url='https://www.baidu.com'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
}
# 构建代理
proxies= {
'http':'47.122.65.254:8080',
'http':'8.130.34.44:8800'
}
response=requests.get(url=url,headers=headers,proxies=proxies)
print(response.content.decode())
# 重试次数设置
import requests
from retrying import retry
# 使用装饰器 retry
@retry(stop_max_attempt_number=3)
def get_html():
url='https://www.baidu.com'
# 3秒超时
response=requests.get(url, timeout=3)
return response.content.decode()
try:
html=get_html()
except Exception as e:
print(e)
# 解析 json
import json
data = [{"name":"张大山","age":11},{"name":"王大锤","age": 13}]
# ensure_ascii=False 是否使用ascii编码
json_str = json.dumps(data, ensure_ascii=False)
print(json_str)
# json字符串转List
loads = json.loads(json_str)
print(loads)
# jsonpath 的使用
pip install jsonpath # 需要安装 jsonpath 库
根元素 # 使用符号 $ 表示JSON文档的根元素。如 $代表整个JSON文档
对象属性 # 使用 . 来选择对象的属性。
# 如 $.name表示JSON中名为name的属性, $..name表示JSON中所有名为name的属性
数组索引 # 用方括号[]来表示数组索引。如 $.students[0]表示JSON中students数组的第一个元素
# 需要注意的是,JsonPath的数组索引是从0开始的,这与XPath从1开始不同
通配符 # 使用 * 表示匹配任意属性或元素。如 $.students[*]表示JSON中所有的students属性
# 而 $.* 表示根元素下的所有属性, $..* 表示所有属性
多个路径表达式 # 使用逗号 , 表示多个路径表达式的组合
# $.students[0].name, $.students[1].age表示JSON中第一个学生的姓名和第二个学生的年龄
过滤表达式 # 使用条件表达式来过滤结果。如,$.students[?(@.age > 18)]表示JSON中年龄小于18岁的学生
import requests
from jsonpath import jsonpath
url='https://www.lagou.com/lbs/getAllCitySearchLabels.json'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)',
}
response=requests.get(url,headers=headers)
a=response.json()
# ret = jsonpath(a, 'jsonpath表达式')
ret=jsonpath(a,'$..name')
print(ret) # ['安阳', '安庆', '鞍山', '安康', '安顺', '澳门']
# xpath 的使用
pip install lxml # 需要安装 lxml 库
nodename # 选中该元素
/ # 从根节点开始选择
// # 选择匹配选择的任何位置的节点
. # 选择当前节点
.. # 选择当前节点的父节点
@ # 选择属性
text() # 选择文本
//title[@lang="eng"] # 选择lang属性值为eng的所有title元素
/bookstore/book[1] # 选取属于 bookstore 子元素的第一个 book 元素
/bookstore/book[last()] # 选取属于 bookstore 子元素的最后一个 book 元素
/bookstore/book[last()-1] # 选取属于 bookstore 子元素的倒数第二个 book 元素
/bookstore/book[position()>1] # 选择bookstore下面的book元素,从第二个开始选择
//book/title[text(='Harry'] # 选择所有book下的title,仅仅选择文本为Harry的title元素
/bookstore/book[price>35]/title # 选取 bookstore 中的 book 的所有 title,且 price 的值大于 35
import requests
from lxml import etree
text = '''<div><ul>
<li class="item-1"><a href="link1.html">link1</a></li>
<li class="item-1"><a href="link1.html">link2</a></li>
</ul></div>'''
html = etree.HTML(text)
print(html)
# 获取文本值
title = html.xpath('//li[@class="item-1"]/a/text()')
print(title[0])
# 获取属性值
link = html.xpath('//li[@class="item-1"]/a/@href')
print(link[0])
# 获取节点
nodes = html.xpath('//li[@class="item-1"]/a')
for node in nodes:
print(node.xpath('./text()'))
print(node.xpath('./@href'))
常用的包 →